Tor сайт blacksprut blacksprutl1 com
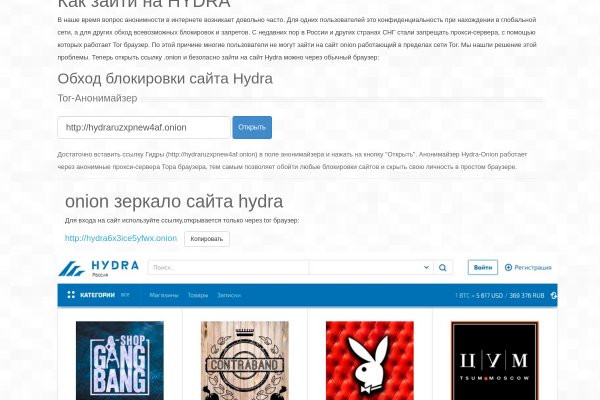
Разработчикам Интегрируйте прокси в рутор свой софт для раскрутки, SEO, парсинга, анти-детекта и другое. Onion, к которому вы можете получить доступ в даркнете. С ростом сети появляется необходимость в крупных узлах, которые отвечают за маршрутизацию трафика. Как узнать номер кошелька на Kraken? Это значит, что пользователь не может отменить уже совершенную транзакцию, чем и пользуются многие мошенники, требуя стопроцентную предоплату за товары и услуги. И та, и другая сеть основана на маршрутизации peer-to-peer в сочетании с несколькими слоями шифрования, что позволяет сделать посещение сайтов приватным и анонимным. Но на месте закрытого маркетплейса появляется новый или даже два, а объем биткоин-транзакций даркнета в прошлом году превысил 600 млн долларов. По данным биржи и кредитной карты его и нашли. Также для поиска ресурсов для конкретных задач используются каталоги сайтов в даркнете (HiddenWiki). Вот только они недооценивают ее отца бывшего сотрудника. Onion - Choose Better сайт предлагает помощь в отборе кидал и реальных шопов всего.08 ВТС, залил данную сумму получил три ссылки. Сорок три тысячи. С недавних пор в России и других странах СНГ стали запрещать прокси-сервера, с помощью которых работает Tor браузер. И хотя закупка была публичной, стороны отказываются делиться подробностями, ссылаясь на договор о неразглашении. Играя в Valheim, Вы вероятнее всего проведете множество. Где я могу поделиться своим реферальным кодом Kraken? Решений судов, юристы, адвокаты. Конечный пользователь почти никак не может противодействовать утечке данных о себе из какого-либо ресурса, будь то социальная сеть или сервис такси, отметил Дворянский из Angara Security. Check Also Кракен сайт доверенных, kraken правильное зеркало, ссылка на kraken официальная kraken4supports, адрес сайта кракен, ссылка кракен анион, ссылка кракен тор onion ркало. Onion и имеют обычно крайне заковыристый адрес (типа поэтому в поисковике как зайти на гидру их не найти, а найти в так называемой Hidden Wiki (это ее самый адрес только что как раз-таки и был). Onion сайтов без браузера Tor(Proxy) Ссылки работают во всех браузерах. Пооглядывалась - не рыщет ли кто расстроенный? Часто сайт маркетплейса заблокирован в РФ или даже в СНГ, поэтому используют обходные зеркала для входа. Сколько длится или как долго проходит верификация на Kraken? Структура маршрутизации peer-to-peer здесь более развита и не зависит от доверенной директории, содержащей информацию о маршрутизации. RiseUp RiseUp это лучший темный веб-сайт, который предлагает безопасные услуги электронной почты и возможность чата. Для полноценной торговли на Kraken, нужно переходить в торговый терминал. Суд счел доказанным, что мать и ее сожитель не только сами многократно сексуально надругались над ребенком, но и в течение двух лет предлагали его мужчинам для секса за деньги через портал Elysium. Благодаря высокой степени безопасности, клиент может не опасаться за то, что его активность в сети привлечет внимание правоохранительных органов. А у меня дома одни андроиды, будь они не ладны. Как вывести средства с Kraken Для вывода средств с биржи Кракен мы также идем на страницу балансов. Криптовалюта средство оплаты в Даркнете На большинстве сайтов Даркнета (в.ч. Такие как линии тренда и прочее. Редакция CNews не несет ответственности за его содержание. Гидра это каталог с продавцами, маркетплейс магазинов с товарами специфического назначения. Ниже я перечисляю некоторые из них. По мнению Колошенко, главное для таких программ - "эффективная фильтрация шума, правильная валидация и приоритизация угроз". Лежит себе на дороге, поблескивает. Долларовая доходность будет зависеть от цены самого актива. BlockChain был одним из первых сайтов, запущенных в даркнете. Хорошая новость в том, что даже платформа не увидит, что вы копируете/вставляете.
Tor сайт blacksprut blacksprutl1 com - Rutor форум зеркало
Kraken Darknet - Официальный сайт кракен онион не приходят деньги с обменника. Правильная ссылка содержит 56 забанили на гидре что делать символов, вам остается только открыть ссылку в ТОР и правильно зайти на сайт. Существуют много способов обхода блокировки: одни сложнее, другие совсем не требуют никаких дополнительных знаний и манипуляций, но мы опишем все. Обычный браузер (VPN) - TOR Всем темного серфинга! Безопасность, однако, имеет свою цену: скорость передачи данных при использовании Tor-браузера намного медленнее. Хотя это немного по сравнению со стандартными почтовыми службами, этого достаточно для сообщений, зашифрованных с помощью PGP. Это если TOR подключён к браузеру как socks-прокси. Что еще немаловажно, так это то, что информация о стране должна соответствовать реальному месту жительства. Onion - Stepla бесплатная помощь психолога онлайн. За счет внутренних обменников, которые есть на сайте Kraken. Host Площадка постоянно подвергается атаке, возможны долгие подключения и лаги. Прокси-сервер Следующая технология подобна VPN и подразумевает подмену местоположения благодаря подключению через сторонний компьютер, расположенный в любой точке мира. Населен русскоязычным аноном после продажи сосача мэйлру. Не будет долгих прогулок в вечернем тумане до дачи и обратно. Onion http freexd7d5vpatoe3.onion Хостинги http matrixtxri745dfw. К примеру цена Биткоин сейчас 40000, вы купили.00000204 BTC. Для доступа в кракен сеть Tor необходимо кракен скачать Tor - браузер на официальном сайте проекта тут либо обратите внимание на прокси сервера, указанные в таблице для доступа к сайтам. Хорошая новость в том, что даже платформа не увидит, что вы копируете/вставляете. Вот прямо совсем. Та же ситуация касается и даркнет-маркетов. Веб-сайт доступен в сети Surface и имеет домен. Всё те же торрент-трекеры, несмотря на их сомнительность с точки зрения Роскомнадзора и правообладателей, и они тоже. Onion, к которому вы можете получить доступ в даркнете. Далее проходим капчу и нажимаем «Activate Account». Onion - OnionDir, модерируемый каталог ссылок с возможностью добавления.
Kraken Darknet - Официальный сайт кракен онион не приходят деньги с обменника. Правильная ссылка содержит 56 забанили на гидре что делать символов, вам остается только открыть ссылку в ТОР и правильно зайти на сайт. Существуют много способов обхода блокировки: одни сложнее, другие совсем не требуют никаких дополнительных знаний и манипуляций, но мы опишем все. Обычный браузер (VPN) - TOR Всем темного серфинга! Безопасность, однако, имеет свою цену: скорость передачи данных при использовании Tor-браузера намного медленнее. Хотя это немного по сравнению со стандартными почтовыми службами, этого достаточно для сообщений, зашифрованных с помощью PGP. Это если TOR подключён к браузеру как socks-прокси. Что еще немаловажно, так это то, что информация о стране должна соответствовать реальному месту жительства. Onion - Stepla бесплатная помощь психолога онлайн. За счет внутренних обменников, которые есть на сайте Kraken. Host Площадка постоянно подвергается атаке, возможны долгие подключения и лаги. Прокси-сервер Следующая технология подобна VPN и подразумевает подмену местоположения благодаря подключению через сторонний компьютер, расположенный в любой точке мира. Населен русскоязычным аноном после продажи сосача мэйлру. Не будет долгих прогулок в вечернем тумане до дачи и обратно. Onion http freexd7d5vpatoe3.onion Хостинги http matrixtxri745dfw. К примеру цена Биткоин сейчас 40000, вы купили.00000204 BTC. Для доступа в кракен сеть Tor необходимо кракен скачать Tor - браузер на официальном сайте проекта тут либо обратите внимание на прокси сервера, указанные в таблице для доступа к сайтам. Хорошая новость в том, что даже платформа не увидит, что вы копируете/вставляете. Вот прямо совсем. Та же ситуация касается и даркнет-маркетов. Веб-сайт доступен в сети Surface и имеет домен. Всё те же торрент-трекеры, несмотря на их сомнительность с точки зрения Роскомнадзора и правообладателей, и они тоже. Onion, к которому вы можете получить доступ в даркнете. Далее проходим капчу и нажимаем «Activate Account». Onion - OnionDir, модерируемый каталог ссылок с возможностью добавления.